| Release Date | Version (Community) | Red Hat Ceph Storage | IBM Storage Ceph |
|---|---|---|---|
| 2024-09-26 | Ceph 19.2 "Squid" | RHCS 8 | IBM Storage Ceph 8 |
| 2023-08-07 | Ceph 18.2 "Reef" | RHCS 7 | IBM Storage Ceph 7 |
| 2022-04-19 | Ceph 17.2 "Quincy" | RHCS 6 | IBM Storage Ceph 6 |
| 2021-03-31 | Ceph 16.2 "Pacific" | RHCS … |
OSD Statistics per pool on Ceph
A simple awk command for analyzing OSD usage in Ceph.

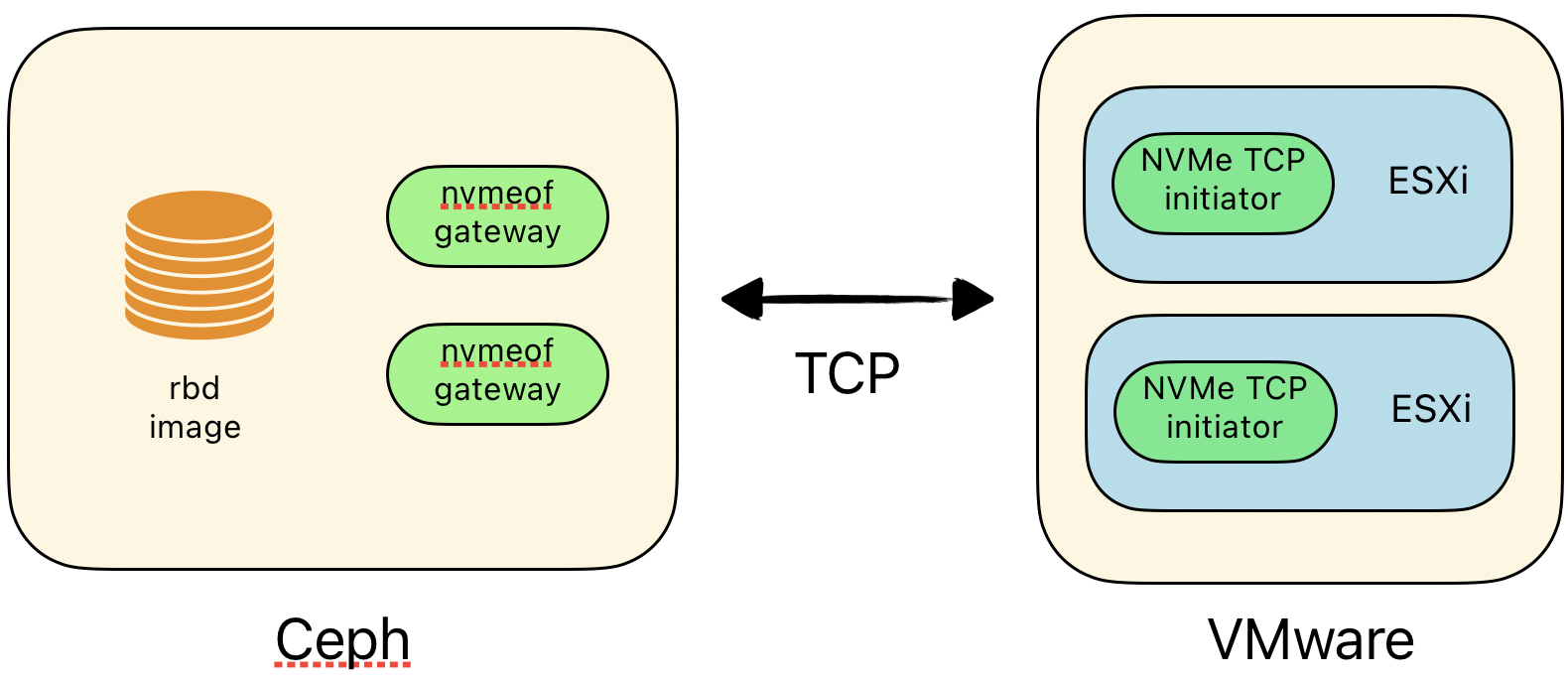
Test Ceph NVMe-oF
A quick test of NVMe over Fabrics (NVMe/TCP) and VMware...
RBD journal offloading
If you are using rbd journaling feature (for example for rbd mirroring), in some cases it could be interesting to offloading journaling on specific pool. For example if your rbd pool is on hdd drives and you also have ssd or nvme.
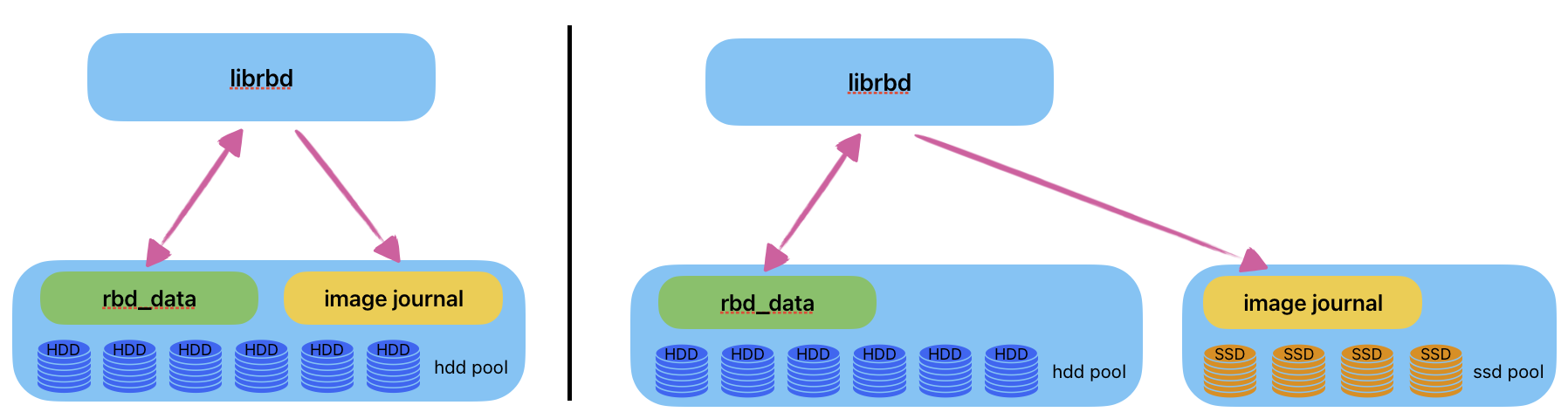
To change rbd journaling pool, there are 2 …
How many mouvement when I add a replica ?
Make a simple simulation !
Use your own crushmap :
$ ceph osd getcrushmap -o crushmap
got crush map from osdmap epoch 28673
Or create a sample clushmap :
$ crushtool --outfn crushmap --build --num_osds 36 host straw 12 root straw 0
2017-07-28 15:01:16.240974 7f4dda123760 1
ID WEIGHT TYPE NAME
-4 …