It is not always easy to know how to organize your data in the Crushmap, especially when trying to distribute the data geographically while separating different types of discs, eg SATA, SAS and SSD. Let's see what we can imagine as Crushmap hierarchy.
Take a simple example of a distribution on two datacenters.
 (Model 1.1)
(Model 1.1)
With the introduction of cache pools we can easily imagine adding ssd drives to our cluster. Take the example of ssd added on new hosts. We then left with two types of disks to manage. In a hierarchy that only describing the physical division of the cluster, we would end up with this type of hierarchy:
 (Model 1.2)
(Model 1.2)
However, we soon realized that this configuration does not allow to separate the types of discs for use in a specific pool.
To separate these discs and organize Crushmap, the simplest method is still to duplicate the tree from the root.
Thus we get two points entered "default" (that could be rename "hdd") and "ssd".
 An other example with hdd and ssd mixed on same hardware (you need to split each host) :
An other example with hdd and ssd mixed on same hardware (you need to split each host) :
 (Model 1.3)
(Model 1.3)
The problem is that we have segmented all the cluster by drive type. It was therefore no more entry point into our tree to select any disk in "dc-1" or in "dc-2". For example, we can no longer define a rule to store data on a specific data center regardless of the type of disc.
What we can do is add other entry points to the root level. For example, to permit access all drives :
 (Model 1.4)
(Model 1.4)
If we wants to keep a certain logic in the tree, it is also possible to add more levels, some more "logical" for exemple for disks types, and other that represent physical distribution.
They can be placed wherever we want and named as we wish. For example, here I added the level "pool" that one could also have called "type" or otherwise.
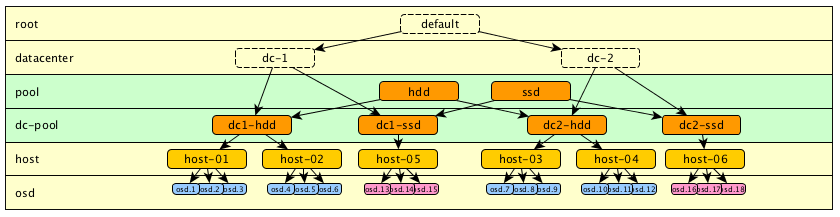
 (Model 1.5)
(Model 1.5)
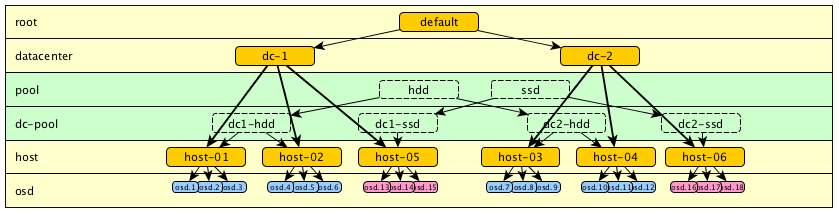
Ok, it works, but it is difficult to read. Moreover, it becomes unreadable when the SSD and HDD are mixed on the same hosts as it involves duplicating each host.
Also, there is no more physical data placement logic. We can try to insert a level between HOST and OSD:
 (Model 1.6)
(Model 1.6)
Ok, it may be advantageous in the case of a small cluster, or in the case where there is no need for other levels.
Let's try something else, we can also try using another organization, such as separating the osd in different levels and use that in the specific rules.
For examble, have step chooseleaf firstn 5 type host-sata to select sata drive, and step chooseleaf firstn 5 type host-ssd to select ssd drive.
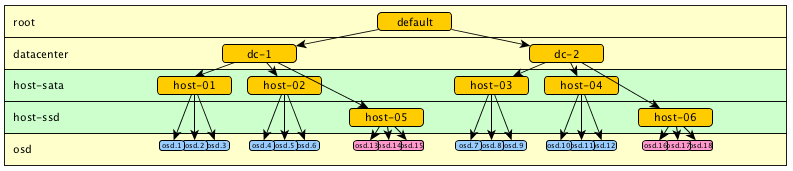 (Model 1.7)
(Model 1.7)
But this do NOT WORK. Indeed, the algorithm will try to take an OSD in each branch of the tree. If no OSD is found, it will try again to retrace. But this operation is quite random, and you can easily end up with insufficient replications.
Make the test of this with this crushmap :
-
1 rule for select one ssd on each DC
-
1 rule for select one sata on each DC
-
1 rule for select one sata on 2 diffrents hosts
# begin crush map
tunable choose_local_tries 0
tunable choose_local_fallback_tries 0
tunable choose_total_tries 50
tunable chooseleaf_descend_once 0
tunable chooseleaf_vary_r 0
# devices
device 0 osd.0
device 1 osd.1
device 2 osd.2
device 3 osd.3
device 4 osd.4
device 5 osd.5
device 6 osd.6
device 7 osd.7
device 8 osd.8
device 9 osd.9
device 10 osd.10
device 11 osd.11
device 12 osd.12
device 13 osd.13
device 14 osd.14
device 15 osd.15
device 16 osd.16
device 17 osd.17
device 18 osd.18
# types
type 0 osd
type 1 host-ssd
type 2 host-sata
type 3 datacenter
type 4 root
# buckets
host-sata host-01 {
alg straw
hash 0
item osd.1 weight 1.000
item osd.2 weight 1.000
item osd.3 weight 1.000
}
host-sata host-02 {
alg straw
hash 0
item osd.4 weight 1.000
item osd.5 weight 1.000
item osd.6 weight 1.000
}
host-sata host-03 {
alg straw
hash 0
item osd.7 weight 1.000
item osd.8 weight 1.000
item osd.9 weight 1.000
}
host-sata host-04 {
alg straw
hash 0
item osd.10 weight 1.000
item osd.11 weight 1.000
item osd.12 weight 1.000
}
host-ssd host-05 {
alg straw
hash 0
item osd.13 weight 1.000
item osd.14 weight 1.000
item osd.15 weight 1.000
}
host-ssd host-06 {
alg straw
hash 0
item osd.16 weight 1.000
item osd.17 weight 1.000
item osd.18 weight 1.000
}
datacenter dc1 {
alg straw
hash 0
item host-01 weight 1.000
item host-02 weight 1.000
item host-05 weight 1.000
}
datacenter dc2 {
alg straw
hash 0
item host-03 weight 1.000
item host-04 weight 1.000
item host-06 weight 1.000
}
root default {
alg straw
hash 0
item dc1 weight 1.000
item dc2 weight 1.000
}
# rules
rule sata-rep_2dc {
ruleset 0
type replicated
min_size 2
max_size 2
step take default
step choose firstn 0 type datacenter
step chooseleaf firstn 1 type host-sata
step emit
}
rule ssd-rep_2dc {
ruleset 1
type replicated
min_size 2
max_size 2
step take default
step choose firstn 0 type datacenter
step chooseleaf firstn 1 type host-ssd
step emit
}
rule sata-all {
ruleset 2
type replicated
min_size 2
max_size 2
step take default
step chooseleaf firstn 0 type host-sata
step emit
}
# end crush map
To test the placement, we can use those commands :
crushtool -c crushmap.txt -o crushmap-new.bin
crushtool --test -i crushmap-new.bin --show-utilization --rule 0 --num-rep=2
crushtool --test -i crushmap-new.bin --show-choose-tries --rule 0 --num-rep=2
Check the utilization :
$ crushtool --test -i crushmap-new.bin --show-utilization --num-rep=2 | grep ^rule
rule 0 (sata-rep_2dc), x = 0..1023, numrep = 2..2
rule 0 (sata-rep_2dc) num_rep 2 result size == 0: 117/1024
rule 0 (sata-rep_2dc) num_rep 2 result size == 1: 448/1024
rule 0 (sata-rep_2dc) num_rep 2 result size == 2: 459/1024
rule 1 (ssd-rep_2dc), x = 0..1023, numrep = 2..2
rule 1 (ssd-rep_2dc) num_rep 2 result size == 0: 459/1024
rule 1 (ssd-rep_2dc) num_rep 2 result size == 1: 448/1024
rule 1 (ssd-rep_2dc) num_rep 2 result size == 2: 117/1024
rule 2 (sata-all), x = 0..1023, numrep = 2..2
rule 2 (sata-all) num_rep 2 result size == 0: 113/1024
rule 2 (sata-all) num_rep 2 result size == 1: 519/1024
rule 2 (sata-all) num_rep 2 result size == 2: 392/1024
For all the rules, the number of replication is insufficient for a part of the sample. Particularly for drives in a minor amount (in that case ssd). Looking at the number of retry to chooose an osd, we see that it will be useless to increase the "choose_total_tries" which is sufficient :
$ crushtool --test -i crushmap-new.bin --show-choose-tries --rule 0 --num-rep=2
0: 4298
1: 226
2: 130
3: 59
4: 38
5: 11
6: 10
7: 3
8: 0
9: 2
10: 1
11: 0
12: 2
$ crushtool --test -i crushmap-new.bin --show-choose-tries --rule 1 --num-rep=2
0: 2930
1: 226
2: 130
3: 59
4: 38
5: 11
6: 10
7: 3
8: 0
9: 2
10: 1
11: 0
12: 2
$ crushtool --test -i crushmap-new.bin --show-choose-tries --rule 2 --num-rep=2
0: 2542
1: 52
2: 12
We can test to increase the number of osd for testing (It's not very pretty...) :
in sata-rep_2dc : step chooseleaf firstn 5 type host-sata
in ssd-rep_2dc : step chooseleaf firstn 5 type host-ssd
in sata-all : step chooseleaf firstn 15 type host-sata
$ crushtool --test -i crushmap-new.bin --show-utilization --num-rep=2 | grep ^rule
rule 0 (sata-rep_2dc), x = 0..1023, numrep = 2..2
rule 0 (sata-rep_2dc) num_rep 2 result size == 1: 1/1024
rule 0 (sata-rep_2dc) num_rep 2 result size == 2: 1023/1024
rule 1 (ssd-rep_2dc), x = 0..1023, numrep = 2..2
rule 1 (ssd-rep_2dc) num_rep 2 result size == 0: 20/1024
rule 1 (ssd-rep_2dc) num_rep 2 result size == 1: 247/1024
rule 1 (ssd-rep_2dc) num_rep 2 result size == 2: 757/1024
rule 2 (sata-all), x = 0..1023, numrep = 2..2
rule 2 (sata-all) num_rep 2 result size == 2: 1024/1024
It's better, we see that for the rule "sata-all" it works pretty well, by cons, when there are fewer disk, the number of replications is always not correct. The idea of this distribution was attractive, but quickly realizes that this can not work.
If people have explored this way, or have examples of advanced CRUSHMAP, I encourage you to share them. I'm curious of all that can be done with this. Meanwhile, the best is yet to make it simple to suit your needs. In most cases, the 1.3 model will be perfect.
More details on CRUSH algorithm : http://ceph.com/papers/weil-crush-sc06.pdf